本文共 3773 字,大约阅读时间需要 12 分钟。
初识领域驱动设计(DDD)
领域驱动设计(DOMAIN-DRIVEN DESIGN),简称DDD,最早是由美国的Eric Evans在2004年提出,主要为了解决应对日益复杂的业务逻辑导致开发困难、软件代码难以维护的问题而提出的软件开发思想。顾名思义,领域驱动设计的核心思想就是对现实世界的业务进行建模,通过领域模型来设计和构造代码,并且代码能够与时俱进,随着业务的发展和开发人员对模型的深入理解而不断完善,以应对不断变化的业务开发迭代。
DDD从概念的提出到现在已经有10多年的时间,一直不温不火,直到近年来微服务的兴起,大家对微服务应该怎么划分,怎样界定各个微服务的系统边界有着疑问,这时人们突然发现DDD的一些核心思想如BOUNDED CONTEXT、AGGREGATE等,能够很好地为微服务提供架构思想。
学习DDD,必定绕不开DDD之父的著作,这本书讲述了DDD的思想和各种概念,比较偏理论。而另外一本则是Vaughn Vernon所著的,这本相对比较新,也更偏向理论的落实和实战,可以结合一起看。
由于DDD我也是最近开始深入了解,目前也只是看了第一本的大部分内容,但是对理解DDD的思想和术语已经有很大帮助了,这篇文章也是针对第一本书的思想总结,如有不对的地方请谅解。
你多久没有用到OO了?
平时总听说“面试造火箭,工作拧螺丝”,我们在公司的开发业务代码其实大部分都在重复做着堆代码的事情。
“这里有个新业务”
“好,那我们建个表,加个service”。
从入行开始,我们就被教导使用三层模型开发,将对象分为domain、dao、service。其中domain就是个POJO,只有Get/Set,没有方法。dao只是为了实现接口而存在,万年不变。service就是实现逻辑的地方,所有的逻辑都放在这里就好了。就好像这样:
public class ServiceAImpl implement ServiceA { private DaoA daoA = new DaoAImpl(); public List methodA(){ return daoA.queryAll(); }} 看起来分工很明确,各层的职责清晰、互不干扰。
这时,来了个新业务B,需要和A的关联起来,就像这样:
public class ServiceAImpl implement ServiceA { private DaoA daoA = new DaoAImpl(); private DaoB daoB = new DaoBImpl(); public List methodA(){ return daoA.queryAll(); } public List methodB() { List aList = methodA(); for(A a : aList) { List bList = daoB.queryBy(a); process(A, bList); // 这里是业务逻辑 } }} 等等,好像哪里不对劲,OO在哪里?根源就在于我们经常用到的三层结构中,domain只是扁平化的贫血对象,没有用到封装继承和多态,而service又把所有的逻辑都揽在一起,随着业务的发展,为了赶工而堆砌的代码都集中在service中,越来越丑陋,想要重构又怕无意中影响到别的功能,导致恶性循环。说白了,我们平时用的三层模型就是个Transaction Script,用的是OO语言,写的却是过程式代码,弃之如敝履,多可惜啊!
而DDD的基础思想就是对我们的业务进行建模,让领域模型(domain)回归到处理逻辑的本质上,通过封装继承和多态等手段实现逻辑的低耦合高内聚,而建模不是一蹴而就的事情,模型随着业务理解的深入不断明确和完善,与业务一起进化。
领域驱动设计的一些关键术语
DDD听起来很复杂,实际上我们需要理解它的一些概念和术语。
UBIQUITOUS LANGUAGE 通用语言
DDD的实施不是一个人的事情,这是需要团队成员都能理解并践行的一套软件设计哲学。DDD的团队主要划分为两类,一个是编写实现代码的程序员,另一个是提出需求的领域专家(其实也就是需求方)。领域专家作为需求提出方,必定最熟悉业务,但是他们一般不懂技术,无法通过精确的语言描述代码实现,而开发人员则恰好相反。由于两者的知识范围和关注点不一样,因此必须建立一个通用语言(UBIQUITOUS LANGUAGE),避免驴头不对马嘴的情况出现。
DDD提倡开发人员和领域专家一起讨论业务实现,大家使用统一的通用语言交流,通过在白板画草图或UML的形式梳理业务、进行抽象建模。
LAYERED ARCHITECTURE 分层架构
有了通用语言,接下来我们看看DDD是如何对应用进行划分的。DDD将应用分为四层,分别是用户界面层、应用层、领域层和基础设施层。
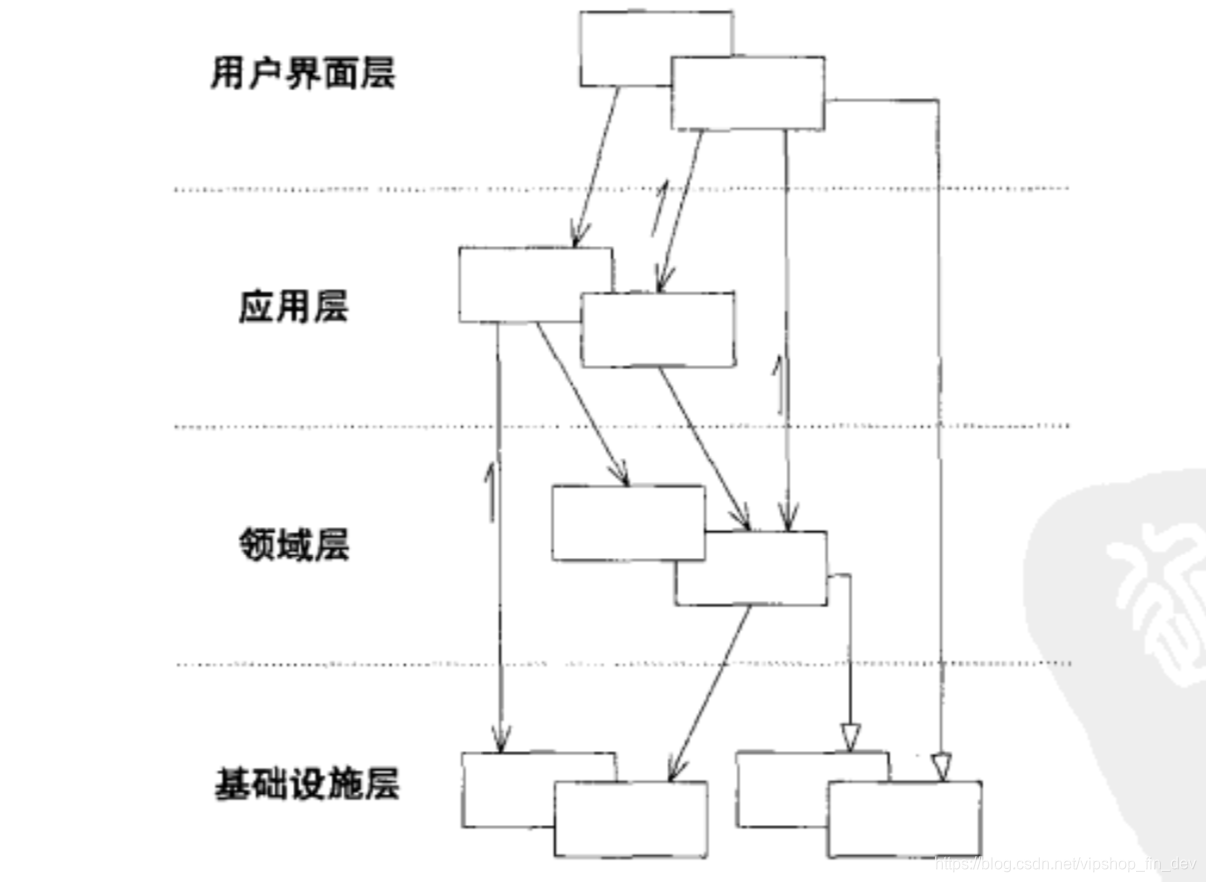
用户界面层
负责向用户显示信息和解释用户指令。这里指的用户可以是另一个计算机系统,不一定是使用用户界面的人。
应用层
定义软件要完成的任务,并且指挥表达领域概念的对象来解决问题。应用层要尽量简单,不包含业务规则或者知识,而只是为下一层中的领域对象协调任务,分配工作,使它们互相协作。
领域层
负责表达业务概念。业务状态信息以及业务规则。尽管保存业务状态的技术细节是由基础设施层实现的,但是反映业务情况的状态是由本层控制并且使用的。领域层是业务软件的核心
基础设施层
为上面各层提供通用的技术能力:为应用层传递信息,为领域层提供持久化机制,为用户界面层绘制屏幕组件,等等。
可以看出,业务逻辑主要由领域层来表达,领域对象应该将重点放在如何表达领域模型上,而不需要考虑自己的显示和存储问题,也无需应用任务等内容。
ENTITY和VALUE OBJECT 实体和值对象
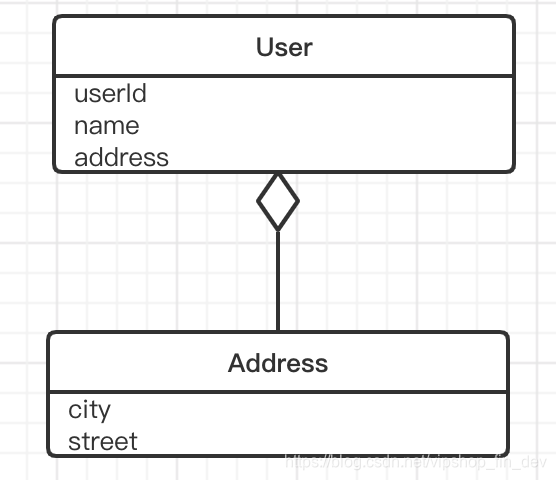
在我们构造核心的领域对象时,有两个概念必须要明确且区分正确,什么是ENTITY,什么是VALUE OBJECT。
在对象建模中,主要由标识定义的对象被称作ENTITY。举个例子,在一个会员系统中,User类就是一个ENTITY,在系统内它可以唯一标记模型对象,一个User就代表一个独一无二的用户。而User类中的name和Address类都是VALUE OBJECT,因为它们不能唯一标识出一个对象。VALUE OBJECT可以认为是ENTITY的属性,可以作为参数在对象之间传递信息,VALUE可以共享,但必须保证是不可变的,如果需要修改,则需要重新创建一个,这个和字符串String有点类似。
AGGREGATE 聚合根
在实现业务过程中,必然会遇到多个领域交互的情况,这时我们就需要划清领域之间的上下文和边界。AGGREGATE就是一组相关对象的集合,我们把它作为数据修改的单元。每个AGGREGATE都有一个根(root)和一个边界(boundary)。边界定义了AGGREGATE内部有什么,根则是AGGREGATE所包含的一个特定ENTITY。对AGGREGATE而言,外部对象只可以引用根,而边界内部的对象之间则可以互相引用。通过这种方式构建的代码能达到低耦合高内聚的效果。
这里列举一下书中的例子:
汽车修配厂的软件可能会使用汽车模型。汽车是一个具有全局标识的ENTITY:我们需要将这部汽车与世界上所有其他汽车区分开(即使是一些非常相似的汽车)。我们可以使用车辆识别号进行区分,车辆识别号是为每辆新汽车分配的唯一标识符。我们可能想通过4个轮子的位置跟踪轮胎的转动历史。我们可能想知道每个轮胎的里程数和磨损度。要想知道哪个轮胎在哪儿,必须将轮胎标识为ENTITY。当脱离这辆车的上下文后,我们很可能就不再关心这些轮胎的标识了。因此,汽车是AGGREGATE的根ENTITY,而轮胎处于这个AGGREGATE的边界之内。另一方面,发动机组上面都刻有序列号,而且有时是独立于汽车被跟踪的。
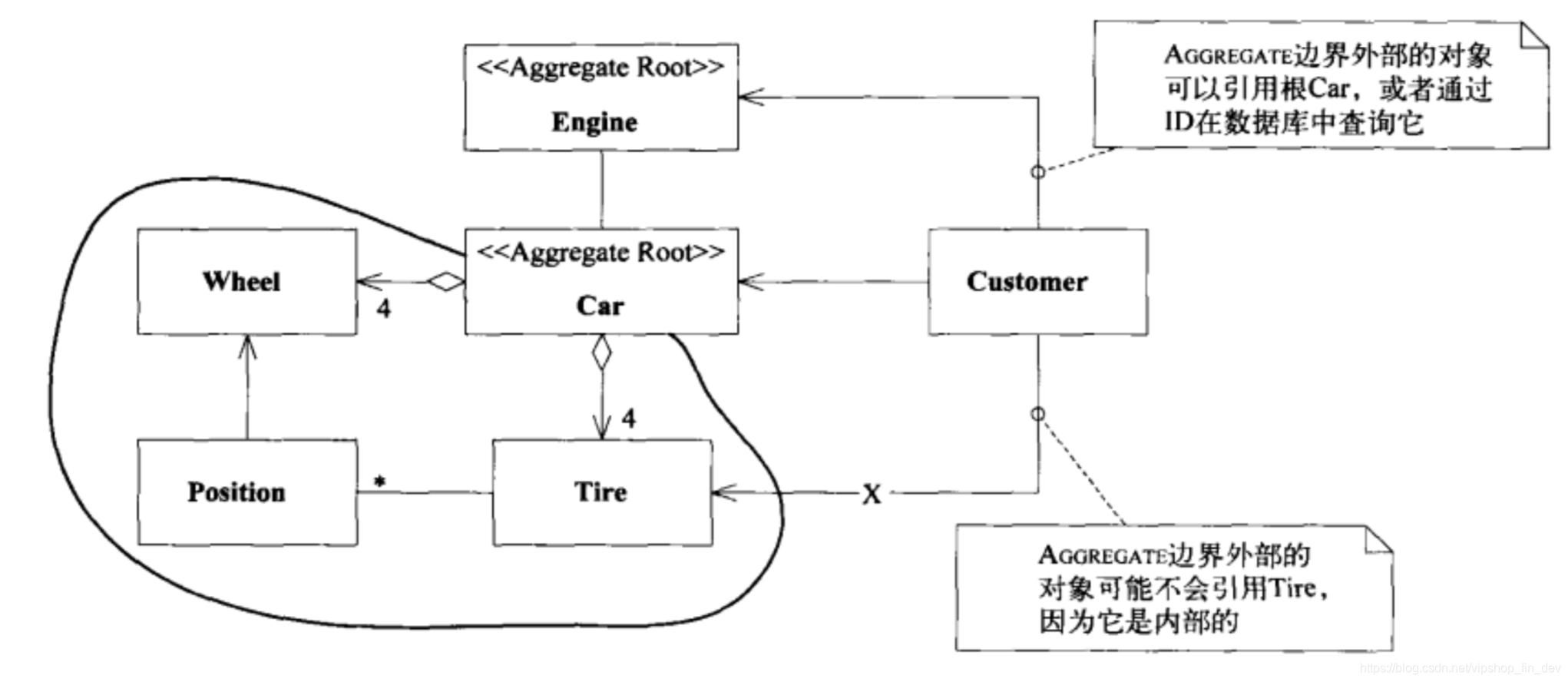
AGGREGATE除了在代码层面划分了边界,在微服务架构上也借鉴了这一思想,不同服务之间也可以通过这一方式确定职责和上下文边界。
实现领域驱动设计的一些关键点
DDD是一套方法论,要实现起来会遇到一些现实问题,比如:
对团队人员提出更高的要求
在大公司角色分工明确,一般会有产品专门与用户(领域专家)对接需求,开发只需对接产品即可,但在DDD中则需要产品也得懂技术建模或者开发也加入到需求探讨中,这对人员的要求更高了。
时刻反思已有模型是否符合业务
建模不是一蹴而就的事情,可能现在的模型在下一次需求迭代的时候就发现不适合了。团队内的开发人员要对DDD的概念理解透彻,并且每次增加需求都要审时现有的模型是否能准确表达业务,否则好不容易建立起的领域模型就被“坏代码”给破坏,后面代码就越来越难维护了。
写在最后
DDD不是银弹,并不是说项目实现了DDD就能解决开发过程中的所有问题,我们需要根据项目实际情况灵活运用。DDD和OO、重构、敏捷开发等思想会一直指导着我们如何构建健壮、可维护的应用。
By Ryan.ou转载地址:http://dwvcz.baihongyu.com/